Honestly, just don't do it. If there's one thing that ChatGPT is bad at, it's
answering obscure NestJS questions. If there is another thing it's bad at, it's telling me
no when something should not be possible.
Instead, what it does is yank me around with hope while giving me convincing looking code
that doesn't quite work.
So, here's what I wanted to do. I'm creating task classes like these:
@DefineTask("Test Task")
export class TestTask implements TaskClass {
constructor(
// (insert other services from the container here)
private readonly host: TaskHost,
) {
}
async execute(): Promise<boolean> {
...
}
}
I wanted all of my program's tasks to implement this interface, where the "task host"
contains the details of the task at hand in addition to utility functions like audit
logging that the task can use while executing.
The thing is, the task host is built by the parent service at the time of instantiation.
Naive me figured that it would be no big deal to pass that along to moduleRef.create
somehow when instantiating the task class. I thought it would be easy to mix that with the
other constructor arguments that come from the container. The short answer is no, it's not
possible. NestJS doesn't provide any way to do it. ChatGPT may tell you otherwise, since
it's terrible at saying no, so I wasted a good amount of time trying to make it work with
research about "context IDs" and such.
The real solution is to not use custom constructor arguments, and instead receive the data
through another interface function, e.g., the execute function in this case.
async execute(host: TaskHost): Promise<boolean>;
But what if?
Curious me wanted to make it work anyway. Not because I really needed to use custom
constructor arguments in my tasks, but because I wanted to know how it all works under the
hood.
To start, the key here is TypeScript. Javascript by itself doesn't have information about
how classes are constructed. In other words, Javascript doesn't have reflection. It's
TypeScript magic that introduces some reflection concepts and allows NestJS to know how to
instantiate objects.
It starts with two cryptic configuration values in the tsconfig.json file:
{
"experimentalDecorators": true,
"emitDecoratorMetadata": true
}
The experimentalDecorators enables decorators in the code, the syntax of @Xyz(...)
that you can attach to classes and properties and such. emitDecoratorMetadata causes all
decorators to add reflection metadata to their targets, available at runtime.
So for example, when you have:
@MyDecorator()
class MyClass {
...
}
TypeScript by itself will see that this is a "decorated" class. For any decorated class,
it will save some "design" metadata about it. The most useful one is design:paramtypes
which dictates what the construction parameter types are. It's a simple array of types,
e.g., [string, number, MyService] etc., corresponding to each constructor argument. It
doesn't matter what the decorator actually does, any decorator use will cause this design
metadata to be emitted (so long as it's enabled in tsconfig).
If Typescript didn't have the design metadata feature, then you would have to decorate
each injection manually, always, as there would otherwise be no way for NestJS to
determine what to inject. For example:
constructor(
@Inject(MyServiceA) private readonly serviceA: MyServiceA,
@Inject(MyServiceB) private readonly serviceB: MyServiceB,
@Inject(MyServiceC) private readonly serviceC: MyServiceC,
)
Versus when you have design metadata to assist with determining what to inject:
constructor(
private readonly serviceA: MyServiceA,
private readonly serviceB: MyServiceB,
private readonly serviceC: MyServiceC,
)
Much more convenient, even if we are breaking the
SOLID principles by depending on a concrete class.
Okay, so back to the goal at hand, getting custom constructor arguments into the
instantiation process. Once you understand the design metadata, the solution becomes
clearer.
The idea is to inspect the construction metadata and then copy it to a separate factory
class. That way, you can intercept the injected arguments, add your own, and then forward
the complete list of arguments to the actual class constructor.
Just one more thing, NestJS will complain that it can't resolve your arbitrary constructor
argument.
Revert to the task class example:
constructor(
private readonly myService: MyService, // Injected from the container
private readonly host: TaskHost, // Injected manually
)
NestJS will complain that it can't resolve TaskHost since it's not defined as a
provider. My solution is to have a custom decorator for those arguments:
constructor(
private readonly myService: MyService, // Injected from the container
@Supplied("host") private readonly host: TaskHost, // Injected manually
)
What @Supplied would do is similar to @Inject. It updates the metadata to describe
that the parameter would be supplied by data from the user under the key "host". It also
calls @Inject using a dummy token SUPPLIED_DEP to resolve the NestJS error.
export const SUPPLIED_DEP = Symbol("supplied-dep");
export const SuppliedDepProvider = {
provide: SUPPLIED_DEP,
useValue: undefined,
};
With this as a provider, NestJS will use undefined as the value for any "Supplied"
parameter, and then it's up to our factory function to fill in the blank. Alternatively,
you could remove the custom arguments from the factory's constructor, but that would
involve modifying the undocumented metadata which would hurt forward compatibility, not to
mention more complex.
The factory function reads the metadata that describes the supplied parameters and
understands which arguments to replace with data from the user, and then forwards the
updated argument list to the real constructor.
See my working example of the hybrid creation
process.
The danger I see with this approach is that we're touching internal reflection data that
is not well documented. For example, the SELF_DECLARED_DEPS_METADATA metadata from
NestJS is copied. This is what contains the @Inject decorations. There might be other
reflection fields that I'm not aware of that are not being handled properly here, and if
anything underneath changes, the code would break. Hence, this is more of a learning
exercise than a recommended approach.

 A fun collaborative canvas with infinite resolution. Not finished yet.
A fun collaborative canvas with infinite resolution. Not finished yet. A SaaS application. Golang container backend. React/Typescript client and Chrome extension. NestJS SaaS/infrastructure management backend. Still growing.
A SaaS application. Golang container backend. React/Typescript client and Chrome extension. NestJS SaaS/infrastructure management backend. Still growing. An anonymous chat server. It's a rite of passage for a programmer to write a chat server.
An anonymous chat server. It's a rite of passage for a programmer to write a chat server. A handy personal tool to track time spent on tasks to chart in a CSV later. I wrote this when I needed to better manage my time in a flexible role and manage SLAs; also to practice C#.
A handy personal tool to track time spent on tasks to chart in a CSV later. I wrote this when I needed to better manage my time in a flexible role and manage SLAs; also to practice C#. Honestly I don't remember much about this. I wanted to simplify creating openvpn profiles, and openssl is a very deep rabbit hole. Here's a
Honestly I don't remember much about this. I wanted to simplify creating openvpn profiles, and openssl is a very deep rabbit hole. Here's a 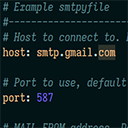 This is a tool I made to simplify reproduction of issues with email networking. A smtpyfile contains delivery parameters and email content, basically a test case for your engineering team.
This is a tool I made to simplify reproduction of issues with email networking. A smtpyfile contains delivery parameters and email content, basically a test case for your engineering team. This is a WebGL application I made to demonstrate expertise in web development while also showing my hobbyist projects. It uses no libraries and is written from scratch.
This is a WebGL application I made to demonstrate expertise in web development while also showing my hobbyist projects. It uses no libraries and is written from scratch. An implementation of Conway's Game of Life.
An implementation of Conway's Game of Life. A tetris game that runs inside of Counter-Strike or other Source games.
A tetris game that runs inside of Counter-Strike or other Source games.  A Mario game that runs inside of Counter-Strike or other Source games.
A Mario game that runs inside of Counter-Strike or other Source games.  A ridiculously fun project that mixes PCM via carefully crafted code. The CPU cycles were hand-counted to time the output of each sample. The sequencer also supports other NES audio channels and extension chips.
A ridiculously fun project that mixes PCM via carefully crafted code. The CPU cycles were hand-counted to time the output of each sample. The sequencer also supports other NES audio channels and extension chips. Programming the SNES by yourself is not for the faint of heart. It was no wonder that the active developer community for this console could be counted on one hand. This was a fun project, complete with audio support from my snesmod library. Music is from various friends in #mod_shrine EsperNet. This game is published via the Super 4 in 1 Multicart.
Programming the SNES by yourself is not for the faint of heart. It was no wonder that the active developer community for this console could be counted on one hand. This was a fun project, complete with audio support from my snesmod library. Music is from various friends in #mod_shrine EsperNet. This game is published via the Super 4 in 1 Multicart. This is a premium SNES audio library that supports streaming audio from the SNES processor to the SPC coprocessor while playing rich Impulse Tracker music. Only a few commercial SNES games like Star Ocean have that functionality.
This is a premium SNES audio library that supports streaming audio from the SNES processor to the SPC coprocessor while playing rich Impulse Tracker music. Only a few commercial SNES games like Star Ocean have that functionality. A fun GameBoy® Advance game.
A fun GameBoy® Advance game. A comprehensive audio engine for the GameBoy® Advance and Nintendo DS. It supports several tracker music formats and software mixing. It can extend the Nintendo® DS's 16 audio channels with additional software channels. Written entirely in ARM assembly.
A comprehensive audio engine for the GameBoy® Advance and Nintendo DS. It supports several tracker music formats and software mixing. It can extend the Nintendo® DS's 16 audio channels with additional software channels. Written entirely in ARM assembly.